Видео с ютуба Text-To-Image Transformer Model

Transformers can do both images and text. Here is why.

Google Launches Muse - A New Text to Image Transformer Model in 2

Muse: Text to Image with Transformers

Manning Introduces: Build a Text‑to‑Image Generator (from Scratch)

An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Paper Explained)

Vision Transformer Quick Guide - Theory and Code in (almost) 15 min

DALL-E: Zero-Shot Text-to-Image Generation | Paper Explained

NO EDITING Needed?! Filmora AI Makes Videos from Just Text (Filmora Text to Video Tutorial)

If LLMs are text models, how do they generate images?

Transformers, explained: Understand the model behind GPT, BERT, and T5

Vision-Transformers for Image Classification AI | How Transformers are used for text to image/video

Google MUSE Text To Image Generation AI Architecture First Look

Text-to-image generation explained

Hugging Face - Text to Image - Getting started in 4 mins

Muse - new AI image Model Architecture from Google

What are Diffusion Models?

Text to Image AI Models: Different methodologies and different models, how it works?

Vision Transformer from Scratch Tutorial

Text to Image generation using ruDALL-E open source Model (DALL-E)
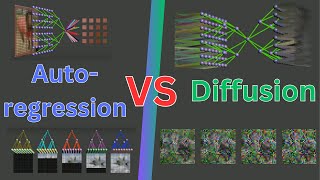
Why Does Diffusion Work Better than Auto-Regression?